



Abstract
Reliable methods for the classification and quantification of quantum entanglement are fundamental to understanding its exploitation in quantum technologies. One such method, known as separable neural network quantum states (SNNS), employs a neural network inspired parameterization of quantum states whose entanglement properties are explicitly programmable. Combined with generative machine learning methods, this ansatz allows for the study of very specific forms of entanglement which can be used to infer/measure entanglement properties of target quantum states. In this work, we extend the use of SNNS to mixed, multipartite states, providing a versatile and efficient tool for the investigation of intricately entangled quantum systems. We illustrate the effectiveness of our method through a number of examples, such as the computation of novel tripartite entanglement measures, and the approximation of ultimate upper bounds for qudit channel capacities.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 licence. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
The core tasks of entanglement classification [1–3] and quantification [4–6] are essential for future quantum technologies, and ask the seemingly straightforward questions: given a quantum state ρ, is it entangled? If so, by how much is it entangled? As the system size or dimension of a quantum system grows, these questions become highly non-trivial and in general there are no universal criteria or methods to provide answers. The most popular mathematical recipe for classification, the positive partial transposition (PPT) criterion (or Peres–Horodecki criterion) [7, 8], applies only to (2 ⊗ 2) or (2 ⊗ 3) bipartite systems. As one extends to multipartite, higher-dimensional quantum systems more sophisticated tools are required.
The application of classical machine learning tools for the study of quantum systems, such as artificial neural networks, have seen a surge of interest due to their remarkable expressive power and efficiency [9–11]. In particular, Carleo and Troyer [12] showed that restricted Boltzmann machines offer a resoundingly appropriate classical representation of quantum states, due to their ability to perform dimensionality reduction, their non-local information distribution, and optimization capacity [13]. Ansatzes based on this architecture are known as neural network quantum states (NNS), and they have been a successful classical simulation tool in a variety of contexts such as tomography [14–17], open quantum system dynamics [18–22], and the study of quantum technologies [23–26].
The versatility of NNS also provides an excellent framework for the study of entanglement [27]. As introduced for pure, qubit states in reference [28], it is possible to manipulate and constrain these neural networks in a way that guarantees a strict form of separability. These constrained variational states are known as separable neural network states (SNNS). Combined with a quantum state reconstruction algorithm, this introduces a unique entanglement witness protocol based on the reconstructive performance of an SNNS with a target state.
In this paper, we generalize these results to mixed, d-dimensional quantum states. We show how SNNS can be used to perform highly specific entanglement classification, and approximate entanglement measures to a very high degree of accuracy. The ability to implicitly characterize the space of separable states is extremely valuable, and allows one to compute entanglement measures that are otherwise extremely difficult to measure, such as the relative entropy of entanglement (REE) [29].
This paper is structured as follows: in section 1 we revise the NNS architecture and its variants for pure and mixed states. Section 2 overviews separable architectures, and shows how specific forms of entanglement can be guaranteed. In section 3 the methods of classification and quantification using SNNS are discussed. Section 4 provides numerical evidence for their utility through a number of relevant examples, with interesting applications in the study of noisy tripartite entanglement, bound entanglement, and quantum channel capacities. Finally, conclusions and future directions are addressed in section 5.
1. Neural network quantum states
1.1. Pure states
The simplest neural network model we can introduce is the positive, real NNS. This model uses a real valued restricted Boltzmann machine (RBM) architecture, with nv
visible units  representing the number of qudits being modelled within the target quantum system, fully interconnected with nh hidden units
representing the number of qudits being modelled within the target quantum system, fully interconnected with nh hidden units  . The visible units are typically binary valued to study d = 2-dimensional systems, si
∈ {−1, 1} as are the hidden units hj
∈ {−1, 1}; however this depends on the system being modelled. This network architecture allows us to capture the correlations of the objective quantum system through network parameters:
. The visible units are typically binary valued to study d = 2-dimensional systems, si
∈ {−1, 1} as are the hidden units hj
∈ {−1, 1}; however this depends on the system being modelled. This network architecture allows us to capture the correlations of the objective quantum system through network parameters:


where a are visible biases, b are hidden biases, and W is the network weight matrix. The total number of parameters is |Π| = nh ⋅ nv + nh + nv (see figure 1).

Figure 1. Neural network quantum state architectures for the simulation of pure states. Panel (a) illustrates the standard NNS construction for n qudits. The visible-layer consists of  units which encode the accessible basis states of the target system; here
units which encode the accessible basis states of the target system; here  is the number of visible units required to encode a single qudit state where
is the number of visible units required to encode a single qudit state where  is some encoding function such that
is some encoding function such that  and its inverse
and its inverse  . Correlations between qudits are captured by an nh unit hidden-layer with interconnected weights and biases. Panel (b) illustrates the amplitude/phase machine that uses two hidden-layers and only real valued parameters.
. Correlations between qudits are captured by an nh unit hidden-layer with interconnected weights and biases. Panel (b) illustrates the amplitude/phase machine that uses two hidden-layers and only real valued parameters.
Download figure:
Standard image High-resolution imageThe inherent advantage offered by the RBM architecture for generative modelling is that there are no intra-layer connections (i.e. there are no connections between adjacent visible units or hidden units). This allows for an ansatz that is independent from the activations of the hidden state space. Thus, one can define a positive NNS wavefunction as [12]

and therefore the NNS is |ΨΠ⟩ = ∑ s ΨΠ( s )| s ⟩.
Whilst NNS have typically been applied to qubit systems using binary visible units, one can extend the modelling to d-dimensional qudits by using a set of visible binary neurons that collectively represent a single qudit [17]. One may choose to encode d-dimensional states using a collection of  visible, binary neurons via an encoding function
visible, binary neurons via an encoding function  , i.e.
, i.e.

The nv
qudit visible-layer can then be encoded into  visible neurons,
visible neurons,

We may identically define the qudit decoding function  such that
such that  . One may encode qudits into binary codes on the visible-layer |s⟩ ↦ bin(s), requiring
. One may encode qudits into binary codes on the visible-layer |s⟩ ↦ bin(s), requiring  visible binary neurons, which however requires d = 2r
for some integer r in order to admit a complete basis set. For arbitrary d it may be more useful to utilize one-hot encoding such that
visible binary neurons, which however requires d = 2r
for some integer r in order to admit a complete basis set. For arbitrary d it may be more useful to utilize one-hot encoding such that  where
where  is a d-length vector that is zero at all indices except index s.
is a d-length vector that is zero at all indices except index s.
In order to study non-positive quantum states one can introduce complex network parameters. Letting ak = αk + iβk , bj = γj + iλj , and Wkj = Γkj + iΛkj , then the NNS wavefunction is

where  , and
, and  . Thus the NNS can exhibit phase properties of quantum states. The network parameter set extends to
. Thus the NNS can exhibit phase properties of quantum states. The network parameter set extends to  .
.
Alternatively one can preserve reality of network parameters by restructuring the nature of the NNS ansatz itself. In particular we can construct an ansatz that uses two RBMs that unify to represent a complete state. Defining a variational phase state ΦΞ( s ), and amplitude state ΨΠ( s ), this network ansatz is given as [14]

Therefore both the variational phase and amplitude networks need only be real valued, since the complex/phase properties of the state are managed through the complex exponential. The state is now defined by two parameter sets,  and
and  .
.
1.2. Mixed states
To extend the variational ansatz to mixed states requires the addition of a hidden mixing-layer with nm hidden units, capable of encoding the classical probability distribution of the mixed quantum state [19–21]. The network state can be constructed from two sets of variational network parameters: Π = {cp
, Ukp
},  and
and  encoding the mixing probabilities [30] and the previously defined
encoding the mixing probabilities [30] and the previously defined  which encodes the pure state probability distribution. Let the density-matrix row and column degrees of freedom be described by basis vectors {
α
,
β
} respectively. As these parameter sets are independent, we may describe a density-matrix element as a contribution from a classical mixing state
which encodes the pure state probability distribution. Let the density-matrix row and column degrees of freedom be described by basis vectors {
α
,
β
} respectively. As these parameter sets are independent, we may describe a density-matrix element as a contribution from a classical mixing state
 and a pure state
σΞ.
and a pure state
σΞ.
The contribution from a classical mixing network is given by


where x* denotes complex conjugation. Meanwhile the pure state contribution is



The complete variational state can therefore be constructed as a sum over all density-matrix elements,

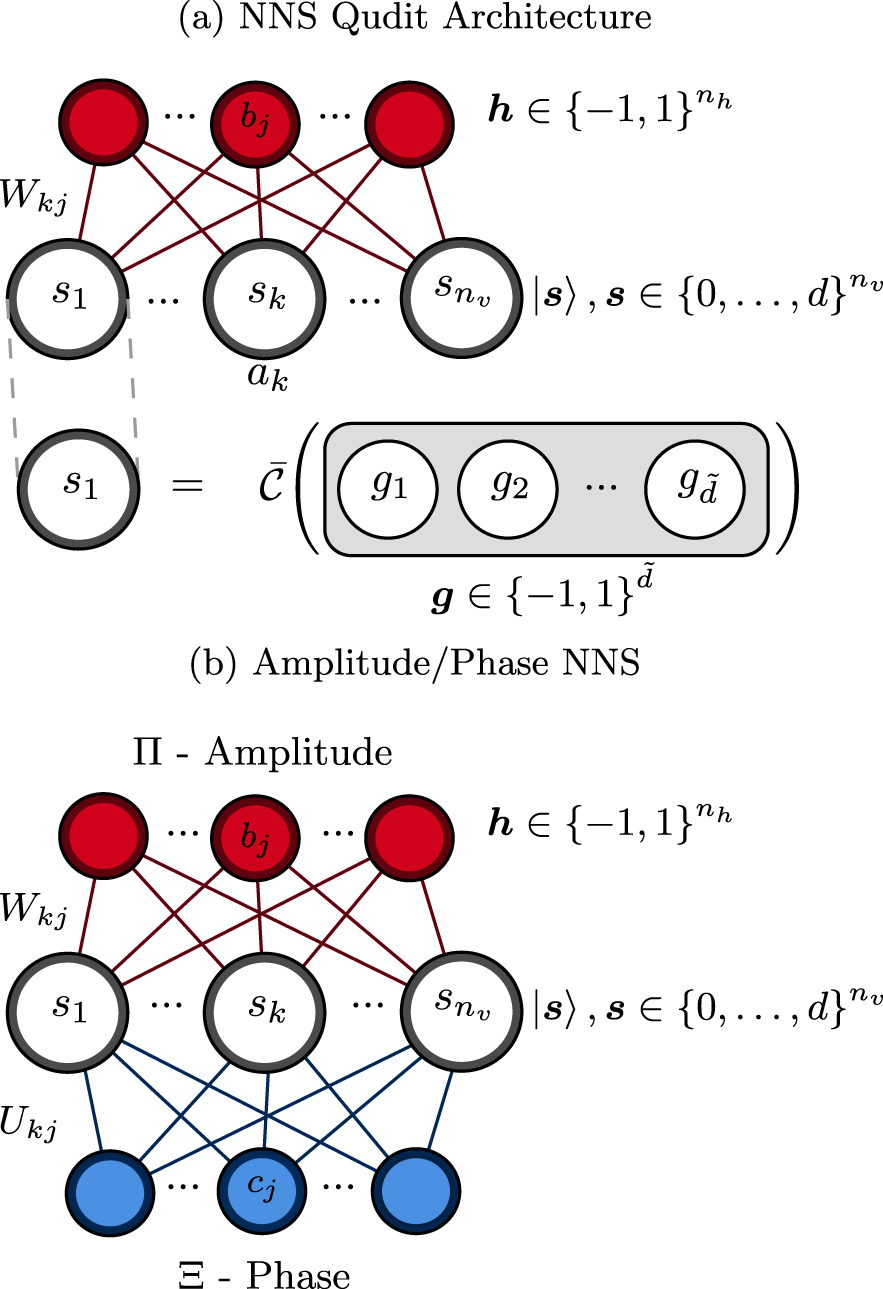
where ⊙ is the Hadamard product. This architecture is presented in figure 2. It is important to emphasize that by construction, the classical mixing state  cannot simulate quantum correlations, only classical correlations (see appendix
cannot simulate quantum correlations, only classical correlations (see appendix

Figure 2. A restricted Boltzmann machine architecture for the simulation of (generally entangled) density matrices using complex parameters.
Download figure:
Standard image High-resolution imageThe network parameters in this ansatz are necessarily complex, thus combining the control of phase and amplitude contributions much like equation (6). However, it may be desirable to formulate an ansatz that is similar to equation (7) in which phase/amplitude contributions are controlled by different networks. One could use the NNS in equation (7) to learn a vectorised density-matrix ρ Π,Ξ = vec(ρΠ,Ξ) = |ρΠ,Ξ⟩, where the function vec(⋅) simply reshapes an n-qudit, dn × dn density-matrix into a d2n column vector. It follows that two real parameter RBMs could then be used to learn phase and amplitude properties respectively, as with pure states. Whilst optimal convergence towards a target vectorised mixed state is possible in this way, the ansatz itself is neither Hermitian or positive semi-definite under reshaping to a matrix. That is, given an inverse vectorisation function vec−1(⋅) which reshapes a d2n column vector into dn × dn density-matrix, then ρΠ,Ξ = vec−1( ρ Π,Ξ) is not a valid density-matrix. Therefore, this form of ansatz may represent states that are non-physical, which is clearly not desirable.
Instead, we can restructure the mixed state ansatz in order to take a closer form to the complex exponential format utilized in the previous section. Let the real parameter sets Ξ, Π be used to describe the pure state phase and amplitude networks respectively, and the complex parameter set Ω used to describe the mixing network. Recall a pure state wavefunction in complex exponential form  . It is useful to define the following functions of our pure density-matrix phase/amplitude wavefunctions
. It is useful to define the following functions of our pure density-matrix phase/amplitude wavefunctions

In order to incorporate classical mixing we need a mixing-layer that takes a similar vectorized form. Omitting the visible biases which are already possessed by the pure states, the mixing-layer takes the form



where Rkp = Re(Ukp ) and Ikp = Im(Ukp ) denote the real and imaginary components of the mixing network respectively. One can then construct the following phase and amplitude functions for the classical mixing


such that the vectorized mixing state takes the form  . This allows for any element of the complete mixed state to be expressed according to
. This allows for any element of the complete mixed state to be expressed according to

2. Separable neural network architectures
2.1. Separable pure network states
Through restrictions on the connectivity of the weight matrix Wkj
, one can guarantee separability of the generative network state. Let us define  as a collection of K-disjoint subsets
as a collection of K-disjoint subsets  , that collect qudit indices from an n-qudit system. More precisely,
, that collect qudit indices from an n-qudit system. More precisely,


In equation (21) we have demanded that the global partition set necessarily contains all n-qudits in the system, and that subsets of qudits are disjoint in equation (22). Hence, an n-qudit, pure state |Ψ⟩ is defined to be  -separable if it can expressed as a tensor-product of sub-states
-separable if it can expressed as a tensor-product of sub-states  , i.e. it is separable with respect to the partition set
, i.e. it is separable with respect to the partition set  . This is a very precise format of separability, as it precisely specifies the arrangement of entangled parties. If we were to disregard specific party orderings we would refer to
. This is a very precise format of separability, as it precisely specifies the arrangement of entangled parties. If we were to disregard specific party orderings we would refer to  -separability.
-separability.
Disjointedness in this definition of  -separability ensures that each qudit is only entangled with respect to a single subset of the quantum system. This provides a specific level of detail to the entanglement structure, while also degenerating many forms of entanglement that we may not be interested in. For example, genuine tripartite entanglement under disjoint
-separability ensures that each qudit is only entangled with respect to a single subset of the quantum system. This provides a specific level of detail to the entanglement structure, while also degenerating many forms of entanglement that we may not be interested in. For example, genuine tripartite entanglement under disjoint  -separability allows for only a single set
-separability allows for only a single set  with no partitions. We may then define non-disjoint
with no partitions. We may then define non-disjoint
 -separability as an extension of the previous definition simply by removing the conditions in equation (22). Using this non-disjoint definition, genuine tripartite entanglement allows for many more definitions,
-separability as an extension of the previous definition simply by removing the conditions in equation (22). Using this non-disjoint definition, genuine tripartite entanglement allows for many more definitions,  , which is studied in later sections (see figure 3 for an example).
, which is studied in later sections (see figure 3 for an example).
To strictly impose either type of separability on an NNS, the goal is to express the wavefunction of the network state in the following form

where  are separable sub-wavefunctions that describe the behaviour of qudits in the partition
k
l
. We may then construct an analogous hidden-layer partition set
are separable sub-wavefunctions that describe the behaviour of qudits in the partition
k
l
. We may then construct an analogous hidden-layer partition set  , which assigns a subset of hidden units to each visible subset of entangled qudits
, which assigns a subset of hidden units to each visible subset of entangled qudits  . By segmenting the layer of hidden units into these K-subsets and applying the following restriction to the weight matrix
. By segmenting the layer of hidden units into these K-subsets and applying the following restriction to the weight matrix

this condition then provides the complete,  -separable network state
-separable network state
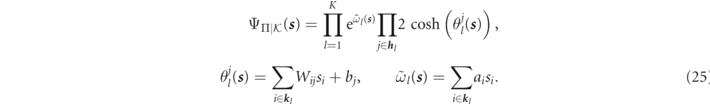
2.2. Separable neural network density matrices
Whilst pure states are  -separable when they can be expressed as the tensor product of
-separable when they can be expressed as the tensor product of  local sub-states, a mixed state possesses a form of separability iff it can be expressed as a convex combination of local sub-states
local sub-states, a mixed state possesses a form of separability iff it can be expressed as a convex combination of local sub-states  . It is now useful to define two distinct forms of separability; consistent and inconsistent mixed-multipartite separability.
. It is now useful to define two distinct forms of separability; consistent and inconsistent mixed-multipartite separability.

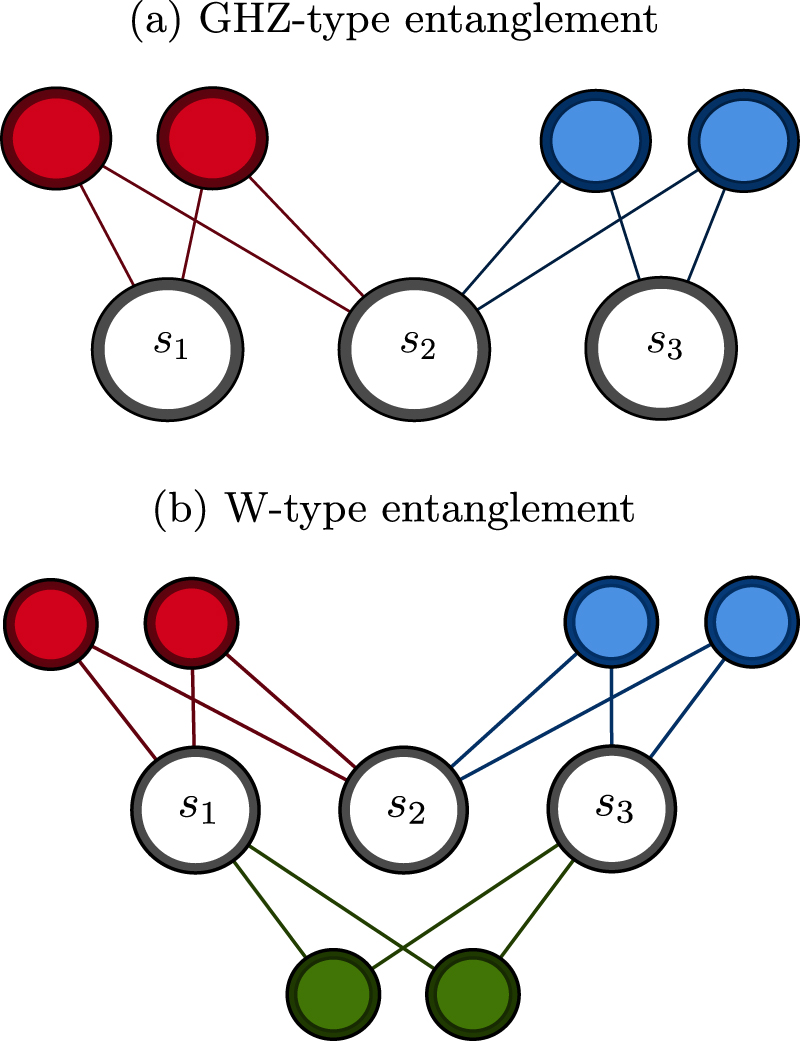
Figure 3. Different pure state network architectures used to simulate genuine tripartite entanglement. Panel (a) depicts a form of GHZ-type entanglement according to the partition set  . Notice that qudits 1 and 3 do not possess a direct connection, but may relay correlations through qudit 2. Panel (b) illustrates a non-disjoint, W-type entanglement structure according to
. Notice that qudits 1 and 3 do not possess a direct connection, but may relay correlations through qudit 2. Panel (b) illustrates a non-disjoint, W-type entanglement structure according to  .
.
Download figure:
Standard image High-resolution imageA state is consistently  -separable if it can be expressed as a convex combination of states which all admit an identical form of separability,
-separable if it can be expressed as a convex combination of states which all admit an identical form of separability,

On the contrary, a state is inconsistently  -separable if it is a mixture of states with different entanglement properties,
-separable if it is a mixture of states with different entanglement properties,

so its entanglement properties are defined by a combination of constituent  -separabilities. Precise classification methods are much more difficult for mixed states, however there are still some very useful approaches that can be introduced using NNS.
-separabilities. Precise classification methods are much more difficult for mixed states, however there are still some very useful approaches that can be introduced using NNS.
Consistently  -separable states require a direct application of the separability conditions given by equation (24) onto the pure state of the NNS. Since the mixing state cannot capture quantum correlations, it is already separable and requires no restrictions. It is thus expedient to apply the separability conditions of equation (24) onto the pure states of the mixed NNS, restricting the capacity of the neural network to simulate quantum correlations. Enforcing separability on the pure density-matrix in this way
-separable states require a direct application of the separability conditions given by equation (24) onto the pure state of the NNS. Since the mixing state cannot capture quantum correlations, it is already separable and requires no restrictions. It is thus expedient to apply the separability conditions of equation (24) onto the pure states of the mixed NNS, restricting the capacity of the neural network to simulate quantum correlations. Enforcing separability on the pure density-matrix in this way

thus provides an NNS guaranteed to be consistently  -separable
-separable

If one wishes to enforce complete separability such that for an n-qudit state  , one can of course just apply consistent separability onto the network state via the separability set
, one can of course just apply consistent separability onto the network state via the separability set  in an identical manner as before. However, as the state is completely separable, there are no quantum correlations and the pure states in the network ansatz are not necessary for simulation of the state. It can then be simplified to
in an identical manner as before. However, as the state is completely separable, there are no quantum correlations and the pure states in the network ansatz are not necessary for simulation of the state. It can then be simplified to  , and we can simulate completely separable mixed quantum systems using an RBM with a classical mixing-layer only [31]
, and we can simulate completely separable mixed quantum systems using an RBM with a classical mixing-layer only [31]

Unfortunately, it is not possible to strictly classify an inconsistently separable mixed state according to ansatzes discussed in this section. Take the tripartite example

which can be thought of as 'cheap' genuine tripartite entangled state. We can certainly define an NNS that can reconstruct a state of this form (trivially, one can utilize a fully connected NNS that can reconstruct ρ); however we cannot specify all three forms of separability in ρ without also allowing the NNS to potentially manifest genuine, pure tripartite entanglement. One can instead utilize independent consistently separable NNS according to the partitions {1, 2|3}, {1, 3|2} and {2, 3|1} in order to quantify the amount of entanglement in the target state with respect to each partition.
3. Classifying and quantifying entanglement
3.1. Learning of quantum states
We present a learning protocol for a pure NNS |ΨΠ,Ξ⟩ to reconstruct a target state |φ⟩ using the ansatz from equation (7), which is then extendible to mixed states. We employ a unified learning approach, where the variational state optimizes the global, vectorized fidelity with a target state, rather than separate phase and amplitude fidelities. We may define the loss function as the negative logarithmic fidelity between two pure states as a function of our set of variational parameters

Splitting these wavefunctions into respective phase and amplitude functions,

we wish to compute the derivatives of the unified cost function with respect to the parameter sets {Π, Ξ}. Since these wavefunctions utilize only real parameters, it is expedient to compute the derivatives using the following chain rule formulation,

Computing these gradients will provide the necessary parameter update rules at the mth iteration to the kth network parameter by gradient descent, taking the form

where η is some learning rate small enough such that the network state converges to the target state over sufficient iterations of the learning scheme.
Defining the quantity

complete gradients with respect to variational parameters can therefore be computed as


where  ,
,  denote diagonal matrices containing the logarithmic derivatives of the network state with respect to the kth amplitude and phase network parameters respectively. Utilizing equation (38) in the update rule given by equation (35), the phase and amplitude properties will optimize in a unified manner, maximizing the fidelity between the network and the target state endowed with non-trivial phase structure.
denote diagonal matrices containing the logarithmic derivatives of the network state with respect to the kth amplitude and phase network parameters respectively. Utilizing equation (38) in the update rule given by equation (35), the phase and amplitude properties will optimize in a unified manner, maximizing the fidelity between the network and the target state endowed with non-trivial phase structure.
Fortunately this learning procedure is readily extended to mixed states via the ansatz in equation (20). Since the variational state is in a complex exponential format, one then formulates a cost function based on the fidelity between the vectorized density-matrix and the vectorized target state. The extension is straightforward and explained in appendix
As shown in reference [28] separable neural network states can be used to perform entanglement classification and provide entanglement measures of pure, two-dimensional quantum states. Using qudit sub-encoding and the mixed state architectures discussed in the previous sections, these ideas can be extended to classification of more complex quantum systems.
Let us devise a precise decision rule for classification. Consider a target n-qudit state σ, a  -separable learner
-separable learner  , and a free, entangled learner
, and a free, entangled learner  which have both been optimized with respect to reconstructing σ. Using the Bures fidelity,
which have both been optimized with respect to reconstructing σ. Using the Bures fidelity,  , we denote the reconstruction fidelity of a learning process as the final/optimal fidelity achieved after a given number of learning iterations. A target σ is learnable via
, we denote the reconstruction fidelity of a learning process as the final/optimal fidelity achieved after a given number of learning iterations. A target σ is learnable via  iff its reconstruction fidelity satisfies
iff its reconstruction fidelity satisfies

for a sufficiently small threshold  . The choice of Fopt determines the reliability of classification, and in our numerical experiments we fix ⩽ 10−4. The accuracy of this reconstruction via free learning also benchmarks the satisfactory computational resources required in the network, informing the separable reconstruction.
. The choice of Fopt determines the reliability of classification, and in our numerical experiments we fix ⩽ 10−4. The accuracy of this reconstruction via free learning also benchmarks the satisfactory computational resources required in the network, informing the separable reconstruction.
One can reliably infer that a target state is  -separable if it is learnable by both a free NNS (
-separable if it is learnable by both a free NNS ( ), and a
), and a  -separable NNS (
-separable NNS ( ). Then the NNS reconstruction fidelities must satisfy
). Then the NNS reconstruction fidelities must satisfy

Otherwise, the state is entangled to a higher degree. One may then quantify the entanglement content of the target by investigating the distance between σ and an approximation to the closest  -separable state.
-separable state.
3.2. Quantifying entanglement
The most difficult aspect of quantifying entanglement stems from the complicated nature of characterising the space of separable quantum states. Thanks to the implicit guarantee of specific separability, SNNS offer an extremely useful tool to help with this, and provide the opportunity to study a variety of entanglement measures that are otherwise much too difficult to explore.
Let us consider measures E that satisfy the general properties of a valid entanglement measure [4]. Many important types of E are constructed as a geometric optimization problem with respect to the space of all fully separable states  . That is, given a target state σ and a distance measure (possibly quasi-distance measure) f,
. That is, given a target state σ and a distance measure (possibly quasi-distance measure) f,



These are entanglement measures which are computed by locating the closest separable state (CSS) σ⋆ to σ, with respect to the distance measure f. For such measures, the employment of SNNS to parameterize the separable states  is extremely useful, as it offers an efficient way to perform this optimization. Furthermore, since SNNS are inherently separable, they will always approximate an upper bound on E, since they are certifiably limited in the quantum correlations that they are able to simulate. This is,
is extremely useful, as it offers an efficient way to perform this optimization. Furthermore, since SNNS are inherently separable, they will always approximate an upper bound on E, since they are certifiably limited in the quantum correlations that they are able to simulate. This is,

To generalize, we may construct a measure  which is analogous to E, but is defined with respect to the space of all states which are at most
which is analogous to E, but is defined with respect to the space of all states which are at most  -separable. Defining the set of all states that are
-separable. Defining the set of all states that are  -separable as
-separable as  , then the set of all states that are at most
, then the set of all states that are at most  -separable is given by [32]
-separable is given by [32]

Assuming a measure of the form equation (41), then we can define



 satisfies all the general properties of an entanglement measure, but now with respect to
satisfies all the general properties of an entanglement measure, but now with respect to  , and is therefore able to classify/quantify more complex forms of entanglement.
, and is therefore able to classify/quantify more complex forms of entanglement.
Let us specify some important entanglement measures which SNNS can utilize, starting from the geometric measure of entanglement (GME) [33]. For pure states, the GME is the maximum fidelity that can be obtained between a target state |σ⟩ and the set of pure, at most  -separable states
-separable states 

For more sophisticated mixed state approaches, it is expedient to employ any number of density-matrix distance measures. Several important examples include the trace distance

where  or the Bures metric
or the Bures metric

where F is the Bures fidelity as before. These quantities are readily approximated via SNNS, and easily specified to different forms of  -separability.
-separability.
Of particular interest is the REE [29], an entanglement measure that has many applications in quantum communications and channel capacities [34]. The REE is based on the quantum relative entropy (QRE), a kind of distance measure between two quantum states where

such that S(ρ||σ) ∈ [0, +∞). Due to its asymmetry and the fact that it is infinite on pure states, it is not a true metric. However, the QRE is an important distinguishability measure between quantum states which provides access to important entropic quantities such as the Shannon entropy. Minimizing the relative entropy with respect to the set of all separable quantum states results in the REE

which can be readily employed with respect to parameterized NNS. This can of course generalize to  given a form of separability. Interestingly, the REE is sub-additive and in general
given a form of separability. Interestingly, the REE is sub-additive and in general

This lets us define a regularized n-shot REE

The single-shot, standard REE alone is an extremely difficult quantity to compute, largely due to the characterization of  and the unruliness of the QRE. Its computation has recently been explored using an active learning strategy [35], in which the authors use active learning to compress
and the unruliness of the QRE. Its computation has recently been explored using an active learning strategy [35], in which the authors use active learning to compress  into a more relevant subset of the separable state space that contributes strongly to the REE. Thanks to the implicit separability of NNS, we may choose an alternative approach where it is possible to optimise some other cost function such as fidelity/trace distance that will simultaneously minimise the QRE towards the optimal REE. In doing so, SNNS should allow for the accurate and efficient approximation of ER, and previously unexplored REEs with respect to other forms of separability
into a more relevant subset of the separable state space that contributes strongly to the REE. Thanks to the implicit separability of NNS, we may choose an alternative approach where it is possible to optimise some other cost function such as fidelity/trace distance that will simultaneously minimise the QRE towards the optimal REE. In doing so, SNNS should allow for the accurate and efficient approximation of ER, and previously unexplored REEs with respect to other forms of separability  .
.
4. Applications and results
4.1. Mixed states in d-dimensions
The most substantial generalisation of the methods introduced in reference [28] is the ability to classify and quantify entanglement in mixed, d-dimensional states. To illustrate this improvement, consider the d-dimensional Werner state, parameterized by

where  is the two-qudit flip operator,
is the two-qudit flip operator,  is the d-dimensional identity operator, and η characterizes the entanglement properties of the state. For η ∈ [−1, 0] the state is entangled, and we can easily quantify this entanglement using the analytically known REE [36],
is the d-dimensional identity operator, and η characterizes the entanglement properties of the state. For η ∈ [−1, 0] the state is entangled, and we can easily quantify this entanglement using the analytically known REE [36],

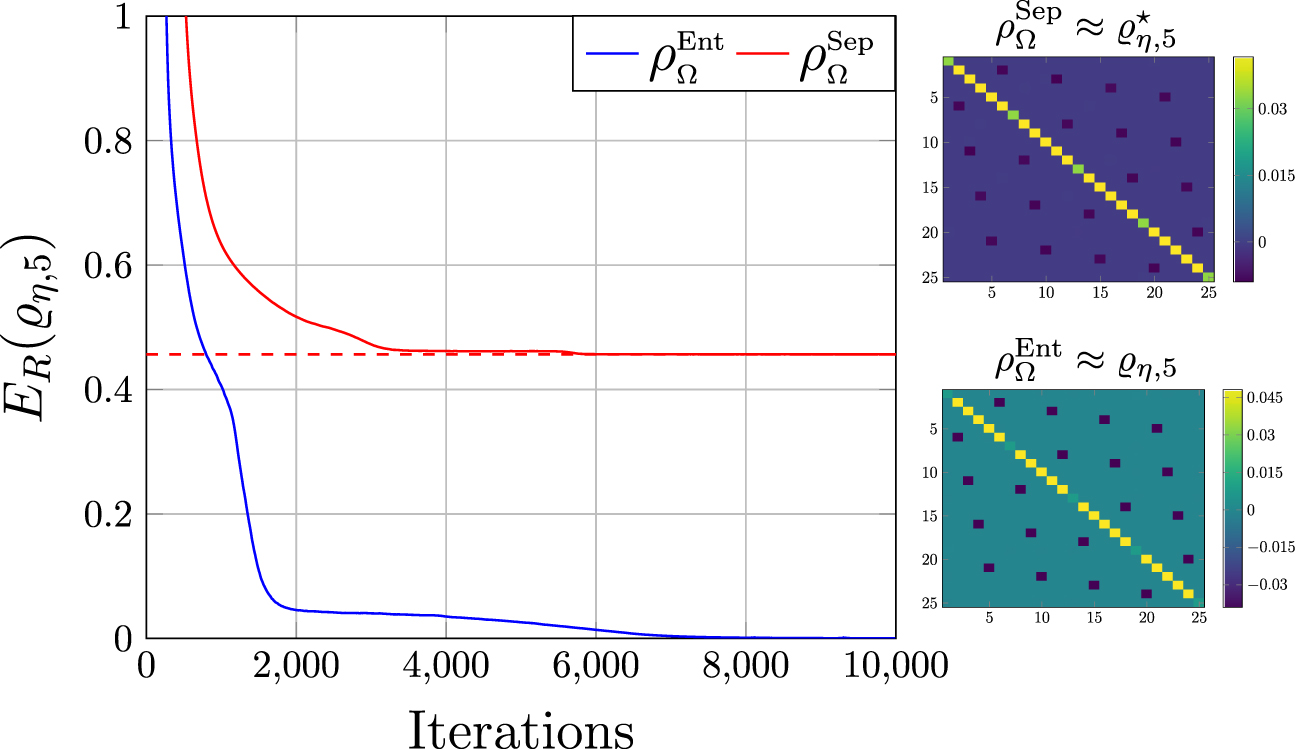
In figure 4 we display an optimization procedure for d = 5, η = −0.75 using an entangled learner  and a fully separable learner
and a fully separable learner  . The free, entangled learner is able to reconstruct the target Werner state with ease, and an extremely high fidelity, while the fully separable learner correctly classifies the target as entangled.
. The free, entangled learner is able to reconstruct the target Werner state with ease, and an extremely high fidelity, while the fully separable learner correctly classifies the target as entangled.

Figure 4. The classification and entanglement quantification of a d = 5 Werner state ϱη,d
, defined in equation (56) for η = −0.75. Using NNS, the REE was approximated to within < 10−5 precision of the known analytical value ER(ϱη,d
) ≈ 0.4564 [36]. The entangled network used 10 hidden mixing neurons and 10 hidden pure state neurons, whilst the separable network used 10 hidden mixing neurons. The density matrices of the (approximate) CSS  and target state approximations are also shown.
and target state approximations are also shown.
Download figure:
Standard image High-resolution imageBeyond the obvious entanglement classification, the SNNS is able to quantify the REE of the state, by monitoring the relative entropy  throughout the learning process. As the optimization converges,
throughout the learning process. As the optimization converges,  , we gather an approximation to the REE of the state. Indeed, under typical optimization settings, the REE is approximated to within < 10−5 precision of the known analytical value ER(ϱ−0.75,5) ≈ 0.4564, reinforcing the strength of this approach.
, we gather an approximation to the REE of the state. Indeed, under typical optimization settings, the REE is approximated to within < 10−5 precision of the known analytical value ER(ϱ−0.75,5) ≈ 0.4564, reinforcing the strength of this approach.
4.2. Classification of bound entangled states
The positivity of a partially transposed quantum system can be a signature of separability. However it is not universal, and there exist classes of states which are PPT but are entangled, known as bound entangled (BE) states. Here we consider the following two-qutrit state,

where  is a d = 3-dimensional Bell state. This state is known to satisfy the following entanglement properties [37]:
is a d = 3-dimensional Bell state. This state is known to satisfy the following entanglement properties [37]:

Here we investigate the target state in the BE region, and show that this bipartite state cannot be optimally reconstructed via SNNS. Figure 5 depicts the employment of entangled learners  (blue), and fully separable learners
(blue), and fully separable learners  (red) to reconstruct σα
across the domain 3 < α ⩽ 4.
(red) to reconstruct σα
across the domain 3 < α ⩽ 4.

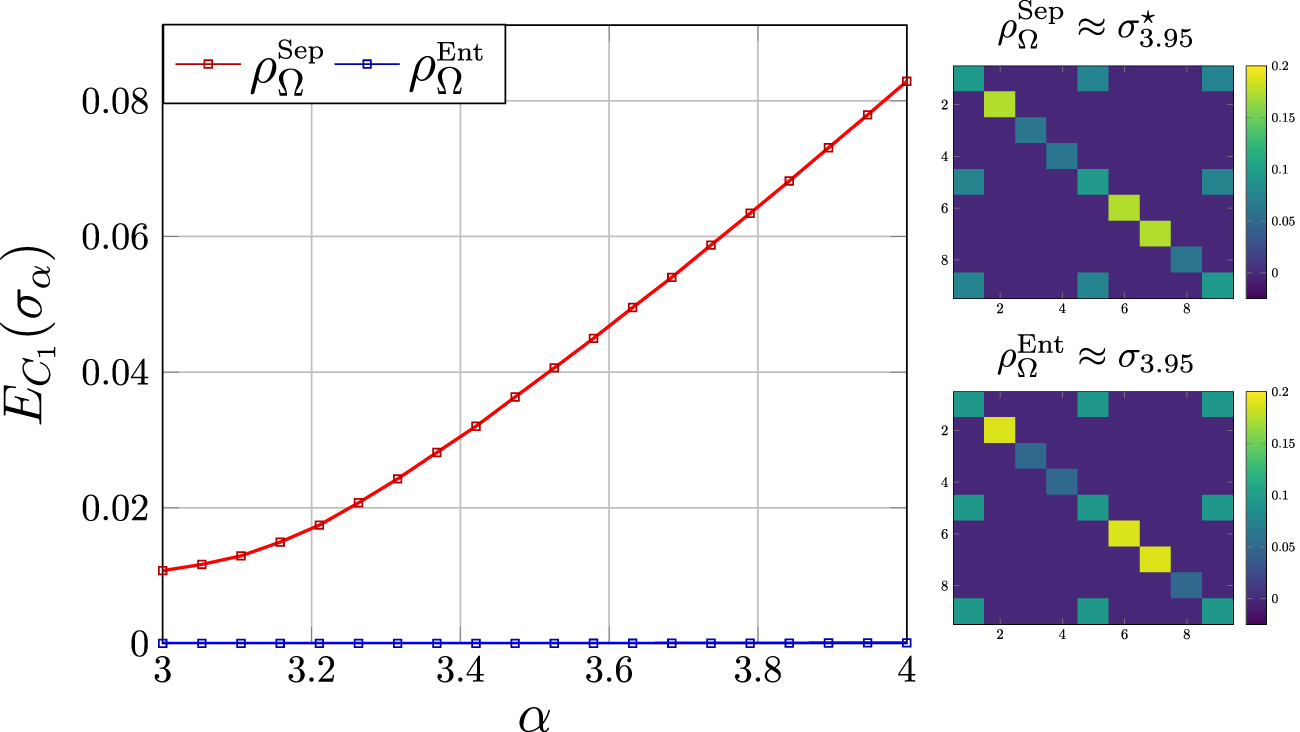
Figure 5. Bound entangled state classification. Entangled learners  (blue) are used to confirm the learnability of the target bound entangled state via NNS. Separable learners
(blue) are used to confirm the learnability of the target bound entangled state via NNS. Separable learners  (red) are then used to classify the target state thus approximate an upper bound on the trace distance from the CSS
(red) are then used to classify the target state thus approximate an upper bound on the trace distance from the CSS  . We also illustrate density matrices of the approximate CSS and the target state for α = 3.95.
. We also illustrate density matrices of the approximate CSS and the target state for α = 3.95.
Download figure:
Standard image High-resolution imageFor all values of α,  is able to reconstruct the state to a high degree of precision such that the trace distance is
is able to reconstruct the state to a high degree of precision such that the trace distance is  . However, the separable learners are unable to reach this level of reconstruction accuracy. Hence, since σα
are learnable via free NNS, the inability of
. However, the separable learners are unable to reach this level of reconstruction accuracy. Hence, since σα
are learnable via free NNS, the inability of  to reconstruct σα
implies that these states are entangled in this region. Since they are also PPT in this region, we have successfully shown the ability of SNNS to classify bound entanglement.
to reconstruct σα
implies that these states are entangled in this region. Since they are also PPT in this region, we have successfully shown the ability of SNNS to classify bound entanglement.
During each constrained optimization we gather an upper bound on the distance between the target BE state, and its CSS. As said before, this is an upper bound since  offers an approximation to the CSS, and is potentially loose. Nonetheless the inferred classification is informative. Figure 5 plots the trace distance
offers an approximation to the CSS, and is potentially loose. Nonetheless the inferred classification is informative. Figure 5 plots the trace distance  , shown to steadily rise as α increases, which is expected as σα
becomes freely entangled for 4 < α ⩽ 5.
, shown to steadily rise as α increases, which is expected as σα
becomes freely entangled for 4 < α ⩽ 5.
4.3. Detection and measurement of multipartite entanglement
The versatility of the  -separable state design means that we can explore entanglement classification and quantification methods that are otherwise very difficult. In particular, we may construct an NNS protocol that is able to witness W/GHZ-state entanglement, and measure W/GHZ-type correlations in both pure and mixed quantum states. Consider the three-qubit W and GHZ states respectively [38, 39]
-separable state design means that we can explore entanglement classification and quantification methods that are otherwise very difficult. In particular, we may construct an NNS protocol that is able to witness W/GHZ-state entanglement, and measure W/GHZ-type correlations in both pure and mixed quantum states. Consider the three-qubit W and GHZ states respectively [38, 39]

These are both maximally entangled three party states. However they possess two inequivalent forms of tripartite entanglement, such that |W⟩ cannot be transformed into |GHZ⟩ by means of LOCC (local operations and classical communications) strategies. The key difference in these forms of entanglement is their robustness i.e. when a party is removed from a GHZ state the remaining states are separable, whilst a W-state remains entangled. Therefore a W-state possesses strict bipartite entanglement between all three parties, whereas GHZ entanglement can be achieved via 'relayed entanglement' [40].
To classify between these states, we must define a partition set that is capable of capturing GHZ correlations, but incompletely capture W-type correlations. The non-disjoint separability set

is capable of learning both W and GHZ entangled states, as it strictly specifies bipartite entanglement between all parties. However, one can construct the partition set

which is any possible permutation of two subsets of  . Programming an NNS according to
. Programming an NNS according to  does not allow the network to capture direct correlations between qubits j and k, and will therefore provide an insufficient ansatz to reconstruct W-states. This forms a witness for W-type entanglement; if a target state is learnable via an NNS endowed with
does not allow the network to capture direct correlations between qubits j and k, and will therefore provide an insufficient ansatz to reconstruct W-states. This forms a witness for W-type entanglement; if a target state is learnable via an NNS endowed with  -separability, but is not learnable via
-separability, but is not learnable via  -separability, then the state is verified as possessing W-type entanglement. Furthermore, by constructing entanglement measures
-separability, then the state is verified as possessing W-type entanglement. Furthermore, by constructing entanglement measures  we are able to measure the amount of W-type correlations within a target state.
we are able to measure the amount of W-type correlations within a target state.
Figure 6(a) shows the pure state classification of a three-qubit W-state, where the non-disjoint network architectures perform classification easily. Note that these three-qubit partitions can be analogously embedded into larger, n-qudit systems in order to study more complex forms of entanglement.

Figure 6. Classification and quantification of d = 2 W/GHZ type entanglement using NNS. Panel (a) shows the classification of W-type entanglement using two NNS designed according to the partition sets  and
and  . If a variational state endowed with
. If a variational state endowed with  -separability can optimally reconstruct a target that
-separability can optimally reconstruct a target that  cannot, then it must possess W-type entanglement. In turn, we locate the closest GHZ-entangled state to |W⟩. In Panel (b) this is extended to mixed, depolarized W/GHZ-states for
cannot, then it must possess W-type entanglement. In turn, we locate the closest GHZ-entangled state to |W⟩. In Panel (b) this is extended to mixed, depolarized W/GHZ-states for  . Panel (c) depicts different versions of the REE upper bounds on a depolarised W-state
. Panel (c) depicts different versions of the REE upper bounds on a depolarised W-state  with respect to depolarising probability. Here we plot three types of REE: The fully separable REE ER (red), the genuine tripartite REE
with respect to depolarising probability. Here we plot three types of REE: The fully separable REE ER (red), the genuine tripartite REE  (green) and the strictly W-type entanglement REE
(green) and the strictly W-type entanglement REE  (blue).
(blue).
Download figure:
Standard image High-resolution imageRealistically, multipartite entangled resources for future quantum communication/computing protocols will be noisy and imperfect. Generating and distributing multipartite entanglement over noisy quantum channels is fundamental for many future quantum technologies, particularly for secure communications and quantum networks [41–48]. Therefore it is a more interesting challenge to consider the classification and quantification of tripartite entanglement subject to decoherence. For instance, one can consider versions of |W⟩/|GHZ⟩ in which each qudit has been passed through a depolarizing channel

where n denotes the number of qudits being acted on (in this case n = 3). We denote these noisy, three-qubit states as


Using mixed NNS programmed with different separabilities, we may then easily distinguish between the entanglement properties of noisy W/GHZ-states subject to depolarizing channels. Indeed, figure 6(b) shows that for  we can perform this classification. Given two learners
we can perform this classification. Given two learners  and
and  , it is clear that both are able to optimally reconstruct the noisy GHZ-state, whilst only
, it is clear that both are able to optimally reconstruct the noisy GHZ-state, whilst only  is able to optimally reconstruct the noisy W-state, completing the classification.
is able to optimally reconstruct the noisy W-state, completing the classification.
This is taken a step further in figure 6(c) where different versions of the REE of  is monitored for various depolarizing probabilities. This plot describes three forms of REE:
is monitored for various depolarizing probabilities. This plot describes three forms of REE:
- The standard ER (red) defined on the space of all fully separable states (using the partition set
 ) which measures the amount of any entanglement present.
) which measures the amount of any entanglement present. - The genuine tripartite entangled REE, (green), using the bi-separable partition sets , which measures the amount of genuine tripartite entanglement in the state (W or GHZ correlations).
- The W-REE, (blue) using the partition set in equation (61), which measures the amount of genuine, tripartite, strictly W-type entanglement within the state.





By employing more complex separable architectures, we may study how different forms of entanglement behave with respect to environmental properties, such as depolarization. By measuring  and
and  for instance, we may monitor the decoherence of genuine tripartite entanglement, rather than any entangle-ment as done so by ER. Such characterizations could prove very useful in communication/networking scenarios, where genuine multipartite entanglement is critical to performance.
for instance, we may monitor the decoherence of genuine tripartite entanglement, rather than any entangle-ment as done so by ER. Such characterizations could prove very useful in communication/networking scenarios, where genuine multipartite entanglement is critical to performance.
It is important to remind the reader that these are upper bounds. The standard REE upper bound is expected to be tight, as fully separable NNS architectures precisely capture full separability. However,  and
and  are degenerate, e.g.
are degenerate, e.g.  has 3 unique forms. Since mixed SNNS are restricted to consistent separabilities, there may be convex combinations of states of these separabilities that produce tighter bounds. It is unknown if this is the case, nonetheless
has 3 unique forms. Since mixed SNNS are restricted to consistent separabilities, there may be convex combinations of states of these separabilities that produce tighter bounds. It is unknown if this is the case, nonetheless  and
and  provide informative upper bounds on these unique entanglement measures.
provide informative upper bounds on these unique entanglement measures.
4.4. Ultimate limits for channel capacities
We may provide a more practical example for the use of SNNS in the realm of quantum communications, using them to approximate upper bounds of quantum channel capacities. Introduced in reference [34], the Pirandola–Laurenza–Ottaviani–Banchi (PLOB) bound is an ultimate upper bound on the two-way assisted quantum (and secret-key) capacity  for a given quantum channel
for a given quantum channel  . Its derivation is based on the techniques of channel simulation and teleportation stretching, which have proven to be extremely versatile in a number of settings [42, 49–53]. An essential class of quantum channels are those which are teleportation covariant, meaning that they satisfy the condition
. Its derivation is based on the techniques of channel simulation and teleportation stretching, which have proven to be extremely versatile in a number of settings [42, 49–53]. An essential class of quantum channels are those which are teleportation covariant, meaning that they satisfy the condition

for some pair of teleportation unitaries {U, V}. Let us define the Choi matrix of a d-dimensional channel  as the result of passing one mode of a maximally entangled state Φ+ through the
as the result of passing one mode of a maximally entangled state Φ+ through the  , and the other through an identity channel
, and the other through an identity channel 

where the maximally entangled state may take the form  . For teleportation covariant channels, the ultimate channel capacity can then be upper bounded in a remarkably simple way [34]
. For teleportation covariant channels, the ultimate channel capacity can then be upper bounded in a remarkably simple way [34]

where ER is the standard REE (and  its n-shot version). SNNS can be used to approximate upper bounds on these channel capacities, via constrained reconstruction of the Choi state of the desired quantum channel.
its n-shot version). SNNS can be used to approximate upper bounds on these channel capacities, via constrained reconstruction of the Choi state of the desired quantum channel.
We consider two important, teleportation covariant, d-dimensional quantum channels in an effort to illustrate the effectiveness of our approach: the depolarizing channel considered in equation (62), and the HW channel [54–56]. The Choi states of these channels are the classes of isotropic states and Werner states respectively, whose REE bounds are known analytically. Therefore, we can compare the numerical performance of computing the REE via SNNS with the known, exact bounds.
Figure 7(a) reports REE bounds on the capacity of depolarising channels for dimensions d = 2, 3, 4. Approximating these bounds via separable network states requires the targeted reconstruction of the isotropic state,

Using a bipartite SNNS  , and attempting to learn the target Choi state leads to an approximation of the REE of said state. Performing this optimization for many depolarizing probabilities p, the results in figure 7(a) can be produced. This is be achieved to a very high degree of accuracy, reproducing the analytical bounds with an average error ∼ < 10−5. Furthermore, these bounds can be computed very efficiently by performing each optimization sequentially, initializing the network parameters using the results of previous optimizations (see appendix
, and attempting to learn the target Choi state leads to an approximation of the REE of said state. Performing this optimization for many depolarizing probabilities p, the results in figure 7(a) can be produced. This is be achieved to a very high degree of accuracy, reproducing the analytical bounds with an average error ∼ < 10−5. Furthermore, these bounds can be computed very efficiently by performing each optimization sequentially, initializing the network parameters using the results of previous optimizations (see appendix

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 7. PLOB channel capacity upper bounds computed via separable neural network states. We plot the exact capacities (continuous plots) against the minimum REE quantities achieved by SNNS (scatter plots, see inset). Panel (a) displays the communication capacities for d = 2, 3, 4-dimensional quantum systems in a depolarizing channel of depolarizing probability p, using mixed, qudit SNNS ansatzes. Panel (b) depicts the capacity for Holevo–Werner (HW) qutrit channels. The network states approximate the REE to a typical accuracy of < 10−5, hence reproducing the capacities to a very high degree of precision.
Download figure:
Standard image High-resolution image{kind=link}
In figure 7(b) we give REE upper bounds for the HW channel, which takes the form

such that T superscript denotes the transposition. The Choi state of the HW channel is the d-dimensional Werner state, introduced in equation (56). The single shot REE bounds for the HW channel are analytically known and given in equation (57), and are independent of dimension d. Again, this single shot bound is approximated to a good precision, as shown in the results.
For Werner states of dimension d > 2, their REE is known to be strictly sub-additive when  , and previous studies have explored the two-shot REE for these Choi states [55], which can therefore be used to tighten these upper bounds. For instance, in figure 7(b) the two-shot capacity can be seen to significantly tighten the bounds for d = 3. In order to compute these tighter bounds, one must modify the definition of the n-shot quantities slightly. Now the minimization is performed with respect to the space of all locally bi-separable states. Consider the n-copy Werner state, and let us label each copy with indices of its modes {i, j},
, and previous studies have explored the two-shot REE for these Choi states [55], which can therefore be used to tighten these upper bounds. For instance, in figure 7(b) the two-shot capacity can be seen to significantly tighten the bounds for d = 3. In order to compute these tighter bounds, one must modify the definition of the n-shot quantities slightly. Now the minimization is performed with respect to the space of all locally bi-separable states. Consider the n-copy Werner state, and let us label each copy with indices of its modes {i, j},

The goal is now to find the CSS that possesses the following bi-separability

where we have permuted the labels into a bi-separable decomposition such that each state belongs to exclusively even or odd mode labels. This corresponds to a situation where two users each possess n local modes, and their goal is to produce the closest state to  that is bi-separable between them. In general this is a very difficult task, and while beyond the scope of this paper, poses as an interesting future application for SNNS.
that is bi-separable between them. In general this is a very difficult task, and while beyond the scope of this paper, poses as an interesting future application for SNNS.
5. Conclusions and outlook
We have generalized the concept of NNS with programmable separability to mixed, d-dimensional quantum states. We discussed a number of neural network architectures for the description of quantum states, and detailed how their entanglement properties may be controlled via constraints placed on network connectivity. It was shown that network connectivity controls entanglement structure on a very specific level, requiring distinctions between certain forms of entanglement. Outlining one of many possible optimisation protocols, methods of classification and quantification via SNNS have been logically developed, and applied in a number of important settings. We then studied a practical application of these tools in the bounding of ultimate quantum channel capacities, showing that they can reproduce the PLOB bounds for DV channels with high precision.
There are a number of valuable future directions in which SNNS may be explored and expanded. While an optimization scheme based on the vectorized fidelity is effective for a variety of applications (as shown in this work) more sophisticated optimization protocols could enhance performance for more specific entanglement measures. In particular, a gradient descent method that directly minimizes the relative entropy (or some variant thereof) would provide a more effective computation of the REE for complex states. This would also lend well to the study of n-shot REE quantities with applications in quantum channel capacities, and the characterization of more complex BE states (such as those constructed from un-extendible product bases). Combining these tools with those from practical quantum tomography could also be extremely useful, e.g. where SNNS may be used to certify the effectiveness an entanglement distribution protocol.
Acknowledgments
CH acknowledges funding from the EPSRC via a Doctoral Training Partnership (EP/R513386/1). MP acknowledges the H2020-FETOPEN-2018-2020 Project TEQ (Grant No. 766900), the DfE-SFI Investigator Programme (Grant 15/IA/2864), COST Action CA15220, the Royal Society Wolfson Research Fellowship (RSWF∖R3∖183013), the Leverhulme Trust Research Project Grant (Grant No. RGP-2018-266), the UK EPSRC (Grant No. EP/T028106/1). SP acknowledges funding from the European Union's Horizon 2020 Research and Innovation Action under Grant Agreement No. 862644 (Quantum readout techniques and technologies, QUARTET).
Data availability statement
The data that support the findings of this study are available upon reasonable request from the authors.
Appendix A.: Neural network mixed state ansatz
We briefly review the construction of the mixed NNS ansatz (see reference [19–21] for more detailed derivations) to illustrate the emergence of the classical mixing state and pure state ansatzes. A generic density-matrix element with respect to row and column basis vectors { α , β } can be expressed as

where pn is the classical probability of a pure state ϕn existing within ensemble, and the sum ∑n may run over many contributing states.
We can use NNS in order to translate this expression into a variational ansatz. As stated in the main text, the inherent advantage to a pure NNS is that its output is independent from the activations of the hidden layer  , which consists of nh neurons. Prior to tracing out this hidden layer, a pure NNS wavefunction is given by,
, which consists of nh neurons. Prior to tracing out this hidden layer, a pure NNS wavefunction is given by,

Using this NNS wavefunction, it is then easy to construct a pure density-matrix, such that  , using two visible layers in order to encode density-matrix entries, as shown in figure (2).
, using two visible layers in order to encode density-matrix entries, as shown in figure (2).
In order to construct the mixed state ansatz, we introduce an additional mixing layer  which is used to represent the classical probabilities
which is used to represent the classical probabilities  , where
, where  are the real-valued hidden mixing neural biases. This mixing layer is interconnected with the visible layers in order to capture classical correlations, mediated via the weight matrix
are the real-valued hidden mixing neural biases. This mixing layer is interconnected with the visible layers in order to capture classical correlations, mediated via the weight matrix  . Combining all the RBM contributions the ansatz reads,
. Combining all the RBM contributions the ansatz reads,

Since there are no intra-layer connections, the hidden layers can be effectively traced out, leaving the mixed state ansatz used in equation (13).
In this work, we make use of a matrix element-wise version of the mixed state decomposition in equation (A1), such that

where  describes classical contributions to the density-matrix, while σ describes quantum contributions from pure states. This representation is readily accessible via the NNS ansatz, and extremely useful for programming forms of entanglement. Importantly, it is by construction that the contributions from the mixing layer are purely classical. On its own, the mixing layer is capable of simulating classical correlations only, and is therefore implicitly separable.
describes classical contributions to the density-matrix, while σ describes quantum contributions from pure states. This representation is readily accessible via the NNS ansatz, and extremely useful for programming forms of entanglement. Importantly, it is by construction that the contributions from the mixing layer are purely classical. On its own, the mixing layer is capable of simulating classical correlations only, and is therefore implicitly separable.
Appendix B.: Learning with complex-exponential ansatz for mixed states
As discussed in section 1.1, one can make use of a restructuring of the mixed state ansatz into complex exponential form in order to take better control of the learning procedure. Indeed, the total mixed state can be expressed as

such that the state is constructed from three variational parameter sets, where rΩ and ΓΠ assume responsibility for the magnitude of any element of the density-matrix, while functions ΦΞ and ϑΩ are responsible for the complex phase of such elements. Consider a target state χ which also admits the following decomposition

The pure density-matrix phase/amplitude functions ΦΞ and ΓΠ respectively, are parameterized by real valued parameter sets. Furthermore, they are decomposed with respect to their pure state wavefunctions, as shown in equation (14). The logarithmic derivatives of the pair of pure state phase functions take the form

while the amplitude function derivatives are

Meanwhile, the mixing state phase/amplitude wavefunctions ϑΩ and rΩ respectively are based on complex parameters. In this case, it is expedient to take derivatives with respect to real and imaginary components, i.e.  ,
,  ,
,  and
and  which can be treated separately. All these derivatives take real, compact and easily derived forms with respect to the neural network parameters, making gradient computations straightforward.
which can be treated separately. All these derivatives take real, compact and easily derived forms with respect to the neural network parameters, making gradient computations straightforward.
The learning procedure of minimising the negative logarithmic fidelity between a target vectorized density-matrix |χ⟩ and the mixed NNS is given by the usual update rule in section 3. Defining the quantity

where ⟨ρΩ,Π,Ξ|χ⟩ is the vectorized overlap between the variational and target state, we can then make use of the following gradients,




Here, |ρΩ,Π,Ξ|2 is the magnitude of the vectorized density-matrix. Furthermore  and
and  are the diagonal matrices with mixing layer gradients. Again, these are treated separately with respect to real and imaginary valued parameters in Ω.
are the diagonal matrices with mixing layer gradients. Again, these are treated separately with respect to real and imaginary valued parameters in Ω.
Appendix C.: Details on numerical simulation
The gradient descent optimization procedures utilized throughout this work were facilitated by an adaptive learning rate scheme using the AdaMax optimizer [57] with a typical initial learning rate of the order ηinit ∈ [10−4, 10−3]. The number of learning iterations varied dependent on the complexity of the target state, i.e. complexity of entanglement needed to be simulated/classified, the dimension of the qudit system being considered (and therefore size of the target density-matrix). Since the time-to-convergence is shorter for states with smaller degrees of entanglement, it is intuitively more efficient to perform classification with a separable NNS than to explicitly reconstruct an entangled state.
A scenario in which the efficiency of learning can be greatly enhanced is the study of evolving, or 'nearby' states. Consider the results from figures 5–7. In a number of instances, we are classifying/quantifying the entanglement of a target state which is changing incrementally (and by a small amount) throughout an interval. Consider an NNS ρΩ that learns a state σ. It is logical to assume that if the target state is perturbed/evolved by some small amount, σ' = σ + δσ, the network Ω will only need to be optimized by a small amount Ω' = Ω + δΩ. Therefore, when studying evolving target states, it is extremely useful to initialize each state using the parameter distribution of the previous learner. This not only simplifies learning and performance, but increases efficiency dramatically; the initial target can be reconstructed over a number of optimization steps S, but subsequent alterations to the network only require a fraction of S steps.
Importantly, when performing this method with SNNS one should ensure that the chosen initialization complies with the entanglement properties of the separable variational state, i.e. a separable network should be initialized with a nearby separable network state. If an SNNS is initialized in with the network parameters of a nearby entangled NNS, when separability conditions are imposed the network state will change rapidly and potentially end up in a state that is very different to the target, contrary to the desired effect.